IN5800 – Data Pipelines and Architectures
Leif Harald Karlsen
Data pipelines and architectures
Principles for data pipelines
- Separation of concern/modularity
- Encapsulation
- DRY (Do not Repeat Yourself)
- Replayability
- Scalability
- Auditability
- Reliable
Principles of pipelines: From software engineering
- Separation of concern/modularity
- Break code into distinct parts
- Split pipeline into multiple semi-independent parts
- Should be able to execute each independent part independently
- For example:
- Make-rules coupled via dependencies
- Functions and function calls
- Encapsulation
- Hide complexity from caller/user
- Only relevant details should be visible from outside a
module/part
- DRY (Do not repeat yourself)
- Move repeated logic into single callable entity (function, rule,
etc.)
- E.g. how to construct IRIs, translation of units, etc.
- How well have our pipelines followed these principles?
Replayability
- Can execute a pipeline easily and repeatedly
- Simple to execute (e.g. a single Make-rule)
- Idempotent (able to execute pipeline over and over with same
result)
- Enables experimentation
- Easier to reproduce data in case of corruption, systems going down,
etc.
- Easier to test (testing vs. production data)
- How replayable have our pipelines been?
Scalability
- Scale with increase in data (or be easy to make scale)
- Use buffered reading/writing
- Use scalable components and platforms
- DBs instead of files
- Cloud vs. own server
- Distributed vs. centralized
- Make it easy to move (cross-platform, containerized, etc.)
- How scalable have our pipelines been?
Auditability
- Clear what is done, when it is done, and what the result were
- Readable and clear code
- Make results easy to inspect
- Logging and provenance
- Where (source) did the data come from
- Who/what made it
- When was it made
- How auditable have the pipelines we have seen in this course
been?
Reliable
- Fault-tolerant, stop execution on error, etc.
- E.g. Wrap DB-calls into transactions
- Do not execute a step if it has a failed dependency
- How reliable have the pipelines we have seen in this course
been?
Flexible
- Adapt to changes in data sources, types, needs, requirements,
etc.
- These may change often
- Fewer steps/layers may be more efficient, simplier, etc.
- But may be less flexible
- Example: Data
transformation exercises pipelines
- E.g. want to change wind-speed from km/h to m/s
- In general: How flexible have our pipelines been?
Testing and development
- Just like software, pipelines are typically developed in a “safe”
environment
- Testing environment/data vs. production environment/data
Updates
- Data is not static
- New data, updates, deletes, etc.
- Not a problem for virtual pipelines
- Can always execute the pipeline over all the data
- Otherwise, needs to produce difference and update
Canonical data architectures
- Architecture for whole data systems
- Combination of pipelines and structures/formats/systems
- We will see a few examples
- New additions come quite often
- More on this in IN5040 - Advanced Database Systems for Big
Data
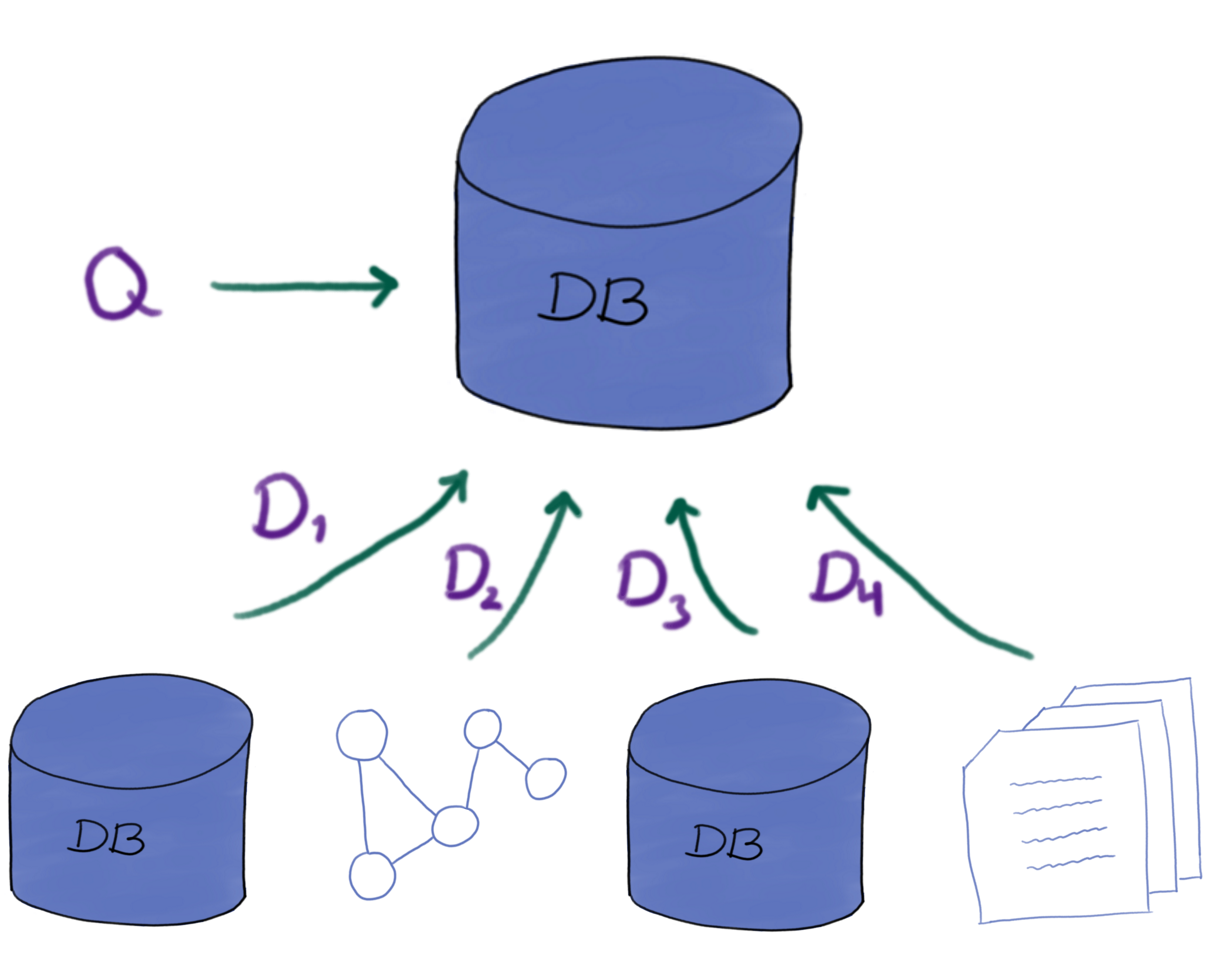
Canonical architectures: Data warehouse
- Store everything in one DB
- Integrates/combines data from production DBs
- Intended for analysis/decision making
- Typically lives alongside other DBs
- Highly structured
- Data mart: Smaller, more domain specific variant
- Main approaches: Normalized or dimensional (Star schema)
Data warehouse: Normalized approach
- Standard normalized schema
- Advantages:
- Easy to add new types of information
- Flexible for analytics
- Disadvantages:
- Inefficient queries (many joins, aggregates)
- More complex schema
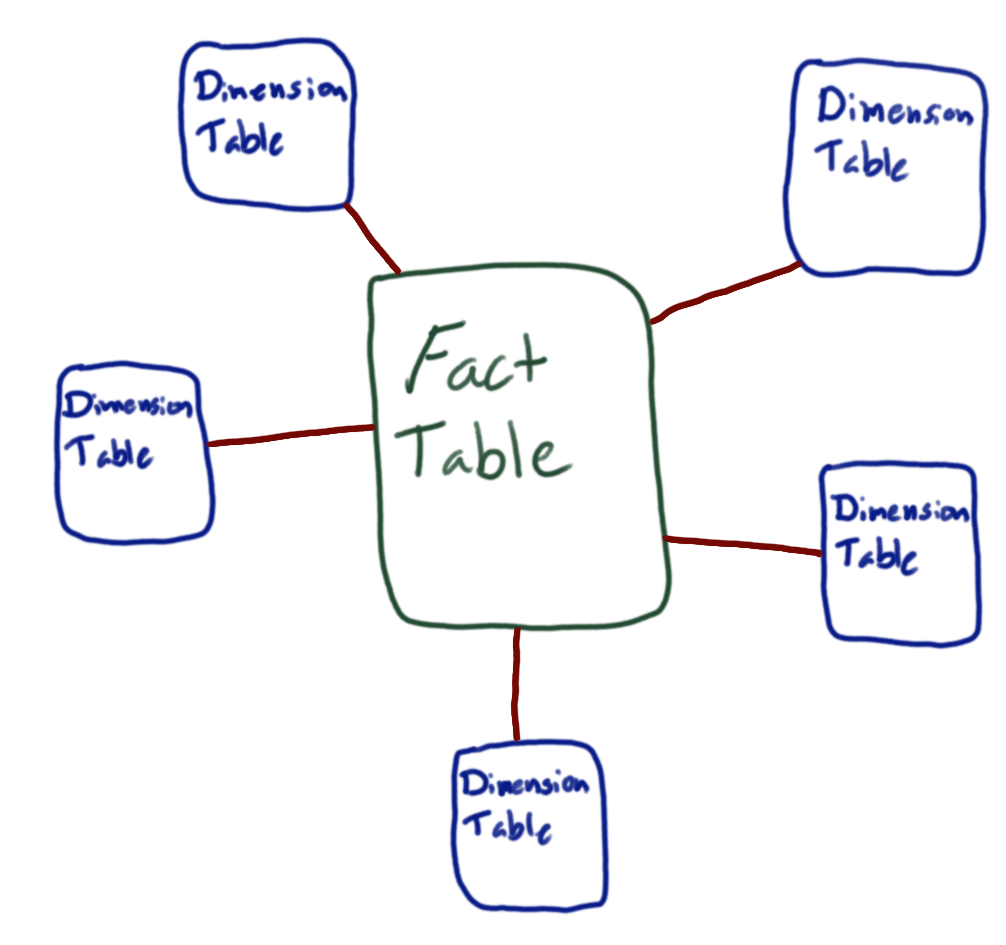
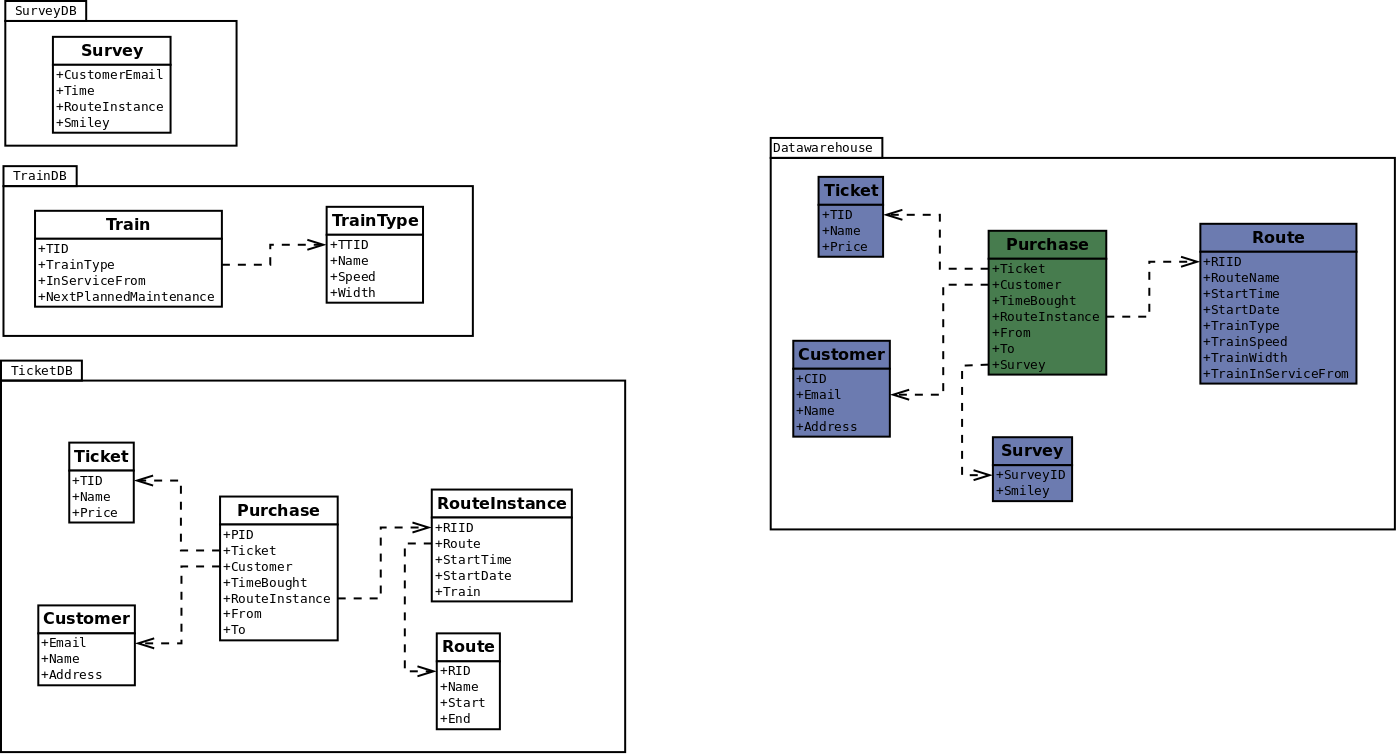
Data warehouse: Dimensional approach
- Most common is perhaps Star Schema
- Tailored for particular use (reporting, analytics, etc.)
- Split data into fact tables and dimension
tables
- Fact tables:
- Record a concrete fact
- Typically numerical values
- Foreign keys to one or more dimensions
- Can also be aggregates
- Dimension tables:
- Describes values/entities of a particular type in more detail
- Often denormalized
- Advantages:
- Efficient queries
- Simpler schema
- Disadvantages:
- Difficult to construct (more complex pipeline)
- Difficult to modify/add new types of information
- Inflexible for analytical purposes
- Normalized dimensional: Snowflake
schema
Dimensional approach: Example
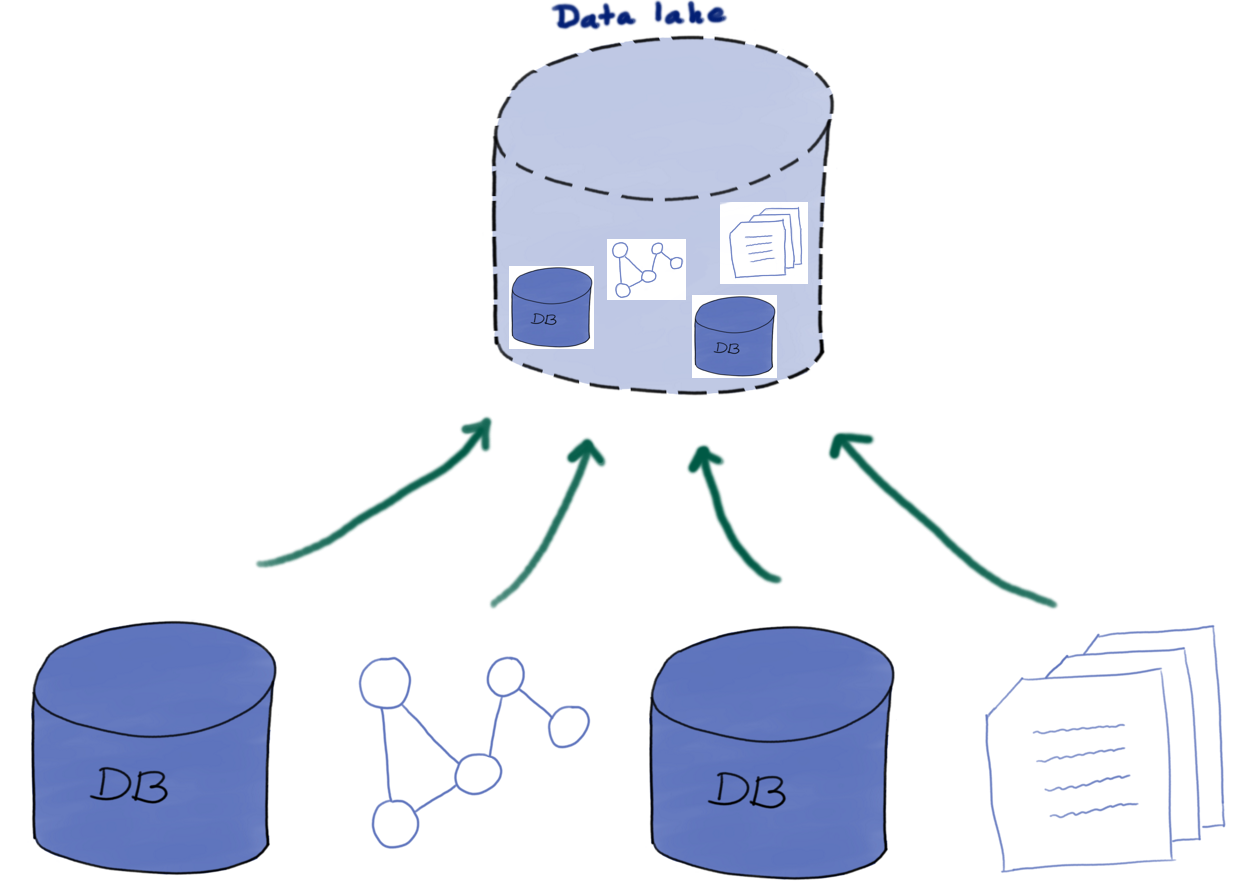
Canonical architectures: Data lake
- Store everything in one DB
- Store everything in its raw form (documents, logs, etc.)
- Need not know how it will be used
- Transform/clean/integrate only when needed
- Attempts to remove “data silos”
Canonical architectures: Data mesh
- Basic idea: Many small, distributed datasets maintained by domain
teams
- In contrast to: Large, central database
- Domain specific
- Distributed
- Managed/owned by a particular team/group
- Data as a product
- Ready to use
- Reliable
- Interoperable
- Discoverable
- Trustworthy
- Self-describing (or documented well)
- …