IN5800 – Declarative Data Engineering
Welcome to a relatively new course!

Welcome to a relatively new course!
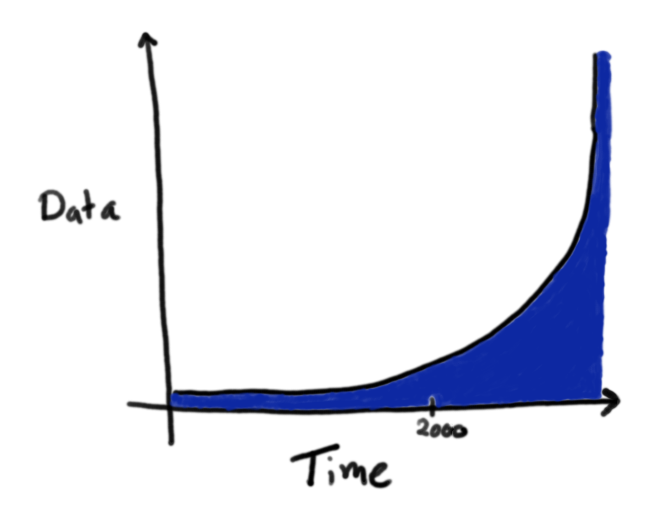
From 2000 onward we have had a sharp increase in:
Managing data size and complexity difficult, in many areas such as:
Big Data is characterized by:

Introduces the need for data-centric roles