Data pipelines
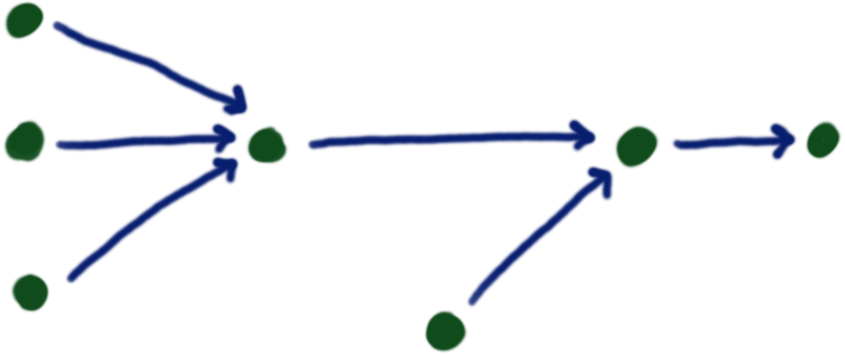
- Can view data transformations as graphs: Sources and targets are nodes, tranformations are edges
- Data pipeline: A collection of data transformation that forms a connected graph
- Will have a separate lecture on data pipelines
Leif Harald Karlsen
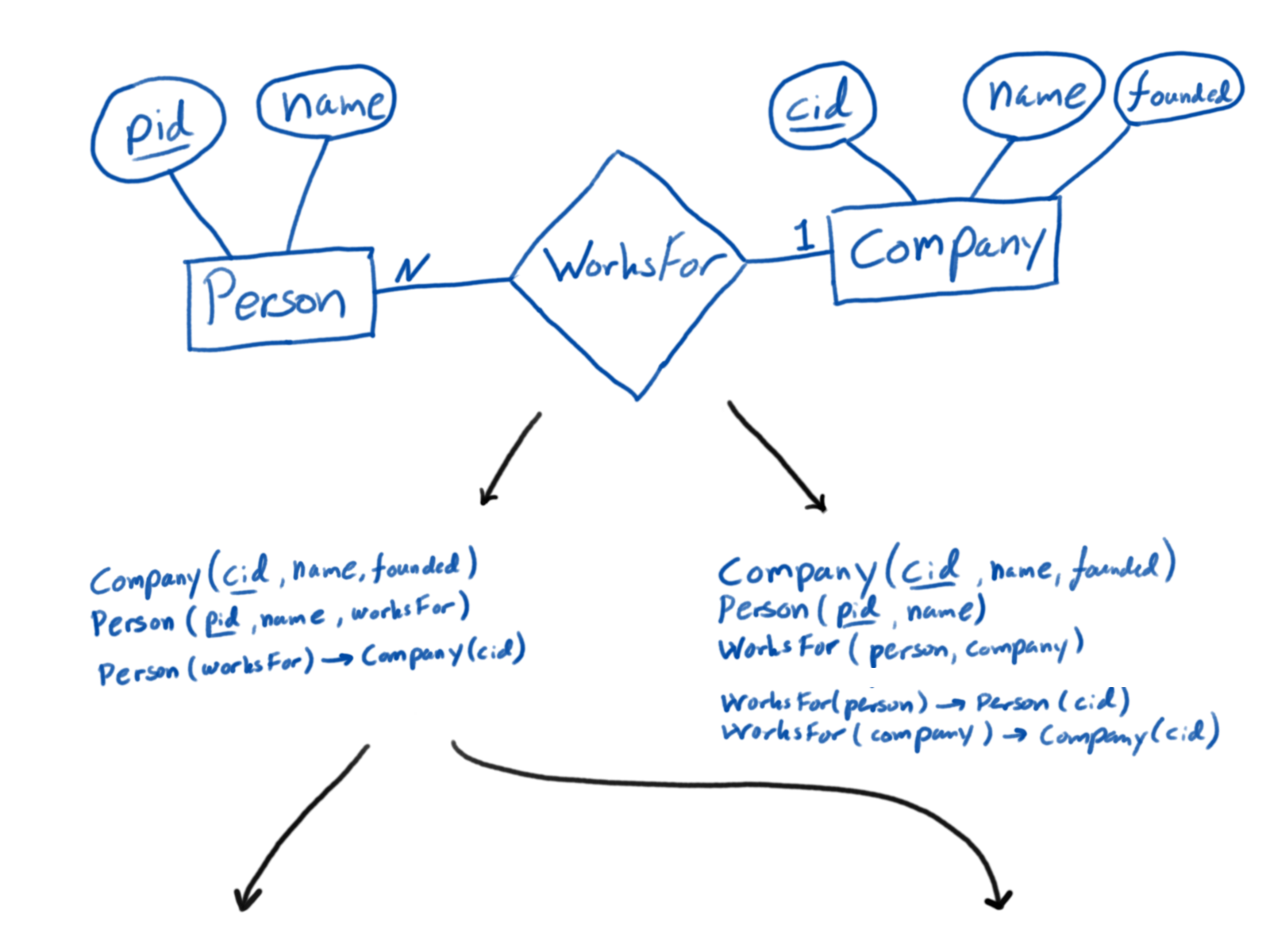

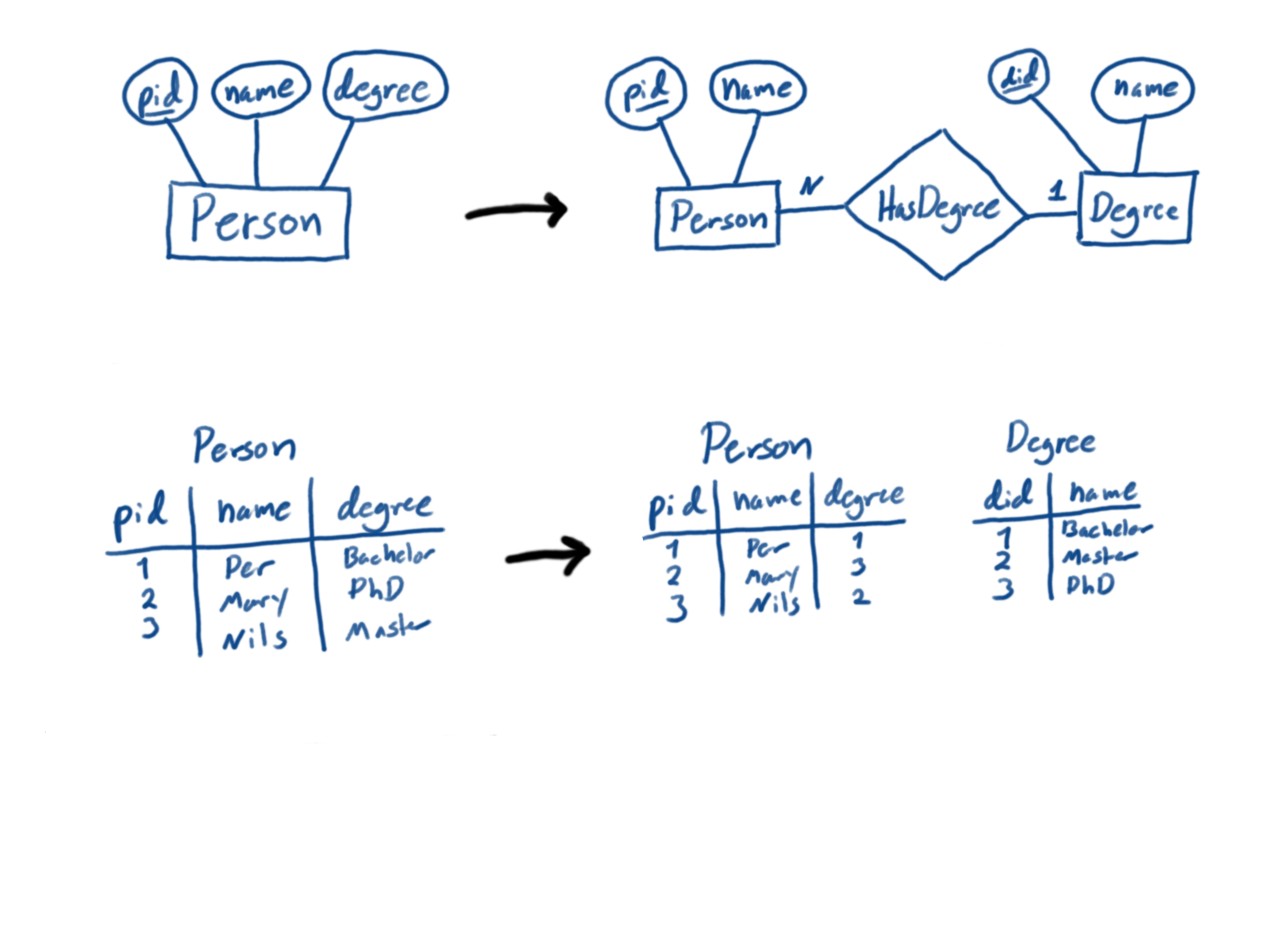
Add an index to a database, e.g.:
Change the type of a column in a database, e.g.:
Add rule to redirect INSERTs
Adding a prefix and refactoring IRIs in RDF
Changing the order of triples in an RDF-file
Changing from row-based to column-based storage
CSVREAD in H2 or COPY FROM in PostgreSQL
(CSV to SQL-table)rdftolore-command (RDF to
Lore-relations) Person
id | name | companyid | companyname
----+------+-----------+-------------
1 | Per | 2 | UiO
2 | Kari | 1 | DNB
3 | Mary | 1 | DNB
3 | Mary | 2 | UiO
||
|| Normalization
\/
Person Company
id | name id | name
----+------ ----+------
1 | Per 1 | UiO
2 | Kari 2 | DNB
3 | Mary
WorksFor
person | company
--------+---------
1 | 2
2 | 1
3 | 1
3 | 2 Person Person_age
id | name | born id | name | born | age
----+------+------------ ----+------+------------+-----
1 | Per | 2001-01-03 ==> 1 | Per | 2001-01-03 | 21
2 | Kari | 1989-06-09 2 | Kari | 1989-06-09 | 31
3 | Mary | 1995-09-08 3 | Mary | 1995-09-08 | 25SELECT-queries: RDF to Tabular
ex:peter ex:hasDegreee "Bachelor" .
ex:mary ex:hasDegreee "Master" .
ex:carl ex:hasDegreee "Master" .
ex:ingrid ex:hasDegreee "PhD" .
||
||
\/
ex:peter a ex:Bachelor .
ex:mary a ex:Master .
ex:carl a ex:Master .
ex:ingrid a ex:PhD .Given the following CSV-file describing authours and the books they have written:
aid, name, isbn, title
1, Peter, 12345, The Troll
1, Peter, 67890, The Troll Returns
2, Mary, 13579, A Planet Adventure
3, Nils, 24680, Caves of Treasure
3, Nils, 13246, Dungeons of GoldProblem: Transform into RDF using the following DC-Terms vocabulary:
@prefix dc: <http://purl.org/dc/terms/>dc:creator: Relates a creator to its workdc:title: Relates a thing to its titledc:identifier: Relates a thing to its unique
identifierdc:BibliographicResource: Class of bibliographic
resources, such as booksdc:Agent: Things that can act, e.g. a personErroneous Solution:
ex:person{aid} ex:<column> <value>ex:name rdfs:subPropertyOf dc:titleResult after first step:
ex:person1 ex:name "Peter" ;
ex:isbn "12345", "67890" ;
ex:title "The Troll", "The Troll Returns" .
ex:person2 ex:name "Mary" ;
ex:isbn "13579" ;
ex:title "The Planet Adventure" .
ex:person3 ex:name "Nils" ;
ex:isbn "24680", "13246" ;
ex:title "Caves of Treasure", "Dungeons of Gold" .Supposed to only be a structural transformation but substantially changed the conceptual schema!
Solution 1:
COPYPerson(id, name),
Book(isbn, title) and Wrote(person, book)ex-p:name rdfs:subPropertyOf dc:titleSolution 2:
Templates:
ex-t:Agent[ ottr:IRI ?person, xsd:string ?name ] :: {
o-rdf:Type(?person, dc:Agent),
ottr:Triple(?person, dc:title, ?name)
}.
ex-t:Book[ ottr:IRI ?book, xsd:string ?isbn, xsd:string ?title ] :: {
o-rdf:Type(?book, dc:BibliographicResource),
ottr:Triple(?book, dc:identifier, ?isbn),
ottr:Triple(?book, dc:title, ?title)
} .
ex-t:Wrote[ ottr:IRI ?person, ottr:IRI ?book ] :: {
ottr:Triple(?person, dc:creator, ?book)
} .bOTTR-mappings:
ex-m:Person a :InstanceMap ;
:template ex-t:Agent ;
:query """SELECT DISTINCT CONCAT('http://example.org/person/', aid), name
FROM CSVREAD('authors.csv', null, 'charset=UTF-8 fieldSeparator=,');""" ;
:argumentMaps (
[ :type :IRI ]
[ :type xsd:string ]
) ;
:source
[ a :H2Source ] .
ex-m:Book a :InstanceMap ;
:template ex-t:Book ;
:query """SELECT DISTINCT CONCAT('http://example.org/book/', isbn), isbn, title
FROM CSVREAD('authors.csv', null, 'charset=UTF-8 fieldSeparator=,');""" ;
:argumentMaps (
[ :type :IRI ]
[ :type xsd:string ]
[ :type xsd:string ]
) ;
:source
[ a :H2Source ] .
ex-m:Agents a :InstanceMap ;
:template ex-t:Wrote ;
:query """SELECT DISTINCT CONCAT('http://example.org/person/', aid), CONCAT('http://example.org/book/', isbn)
FROM CSVREAD('authors.csv', null, 'charset=UTF-8 fieldSeparator=,');""" ;
:argumentMaps (
[ :type :IRI ]
[ :type :IRI ]
) ;
:source
[ a :H2Source ] .Result:
ex-p:1 rdf:type dc:Agent ;
dc:title "Peter" ;
dc:creator ex-b:12345, ex-b:67890 .
ex-p:2 rdf:type dc:Agent ;
dc:title "Mary" ;
dc:creator ex-b:13579 .
ex-p:3 rdf:type dc:Agent ;
dc:title "Nils" ;
dc:creator ex-b:13246, ex-b:24680 .
ex-b:12345 rdf:type dc:BibliographicResource ;
dc:title "The Troll" ;
dc:identifier "12345" .
ex-b:13246 rdf:type dc:BibliographicResource ;
dc:title "Dungeons of Gold" ;
dc:identifier "13246" .
ex-b:13579 rdf:type dc:BibliographicResource ;
dc:title "A Planet Adventure" ;
dc:identifier "13579" .
ex-b:24680 rdf:type dc:BibliographicResource ;
dc:title "Caves of Treasure" ;
dc:identifier "24680" .
ex-b:67890 rdf:type dc:BibliographicResource ;
dc:title "The Troll Returns" ;
dc:identifier "67890" .Want to do some analysis on statistics on open positions by domain:
CREATE SCHEMA stillinger;
CREATE TABLE stillinger.original(
domain text,
y2010 int,
y2011 int,
y2012 int,
y2013 int,
y2014 int,
y2015 int,
y2016 int,
y2017 int,
y2018 int,
y2019 int,
y2020 int,
y2021 int,
y2022 int
);
-- data from https://www.ssb.no/statbank/table/08836/tableViewLayout2/
\copy stillinger.original FROM 'ledige_stillinger.csv' WITH DELIMITER ';' CSV HEADER; Unfortunately, data is not fit for queries comparing data for arbitrary years, e.g.
Find the domain and pair of consecutive years with highest difference in number of open positions
Need to transpose the data, so that years are part of data and not meta data! I.e.:
INSERT INTO stillinger.transposed
SELECT domain, 2010, y2010 FROM stillinger.original
UNION ALL
SELECT domain, 2011, y2011 FROM stillinger.original
UNION ALL
SELECT domain, 2012, y2012 FROM stillinger.original
UNION ALL
SELECT domain, 2013, y2013 FROM stillinger.original
UNION ALL
SELECT domain, 2014, y2014 FROM stillinger.original
UNION ALL
SELECT domain, 2015, y2015 FROM stillinger.original
UNION ALL
SELECT domain, 2016, y2016 FROM stillinger.original
UNION ALL
SELECT domain, 2017, y2017 FROM stillinger.original
UNION ALL
SELECT domain, 2018, y2018 FROM stillinger.original
UNION ALL
SELECT domain, 2019, y2019 FROM stillinger.original
UNION ALL
SELECT domain, 2020, y2020 FROM stillinger.original
UNION ALL
SELECT domain, 2021, y2021 FROM stillinger.original
UNION ALL
SELECT domain, 2022, y2022 FROM stillinger.original;ex:per ex:hasName "Per" .
||
||
\/
_:s a rdf:Statement ;
rdf:subject ex:per ;
rdf:predicate ex:hasName ;
rdf:object "Per" ._:s ex:createdAt "2023-02-03" ;
ex:madeBy ex:per ;
ex:describes ex:per .
ex:kari ex:knows _:s .Employee and
'Kari' is not listed, we can conclude that
'Kari' is NOT an employeeS is not entailed by the data,
we can conclude NOT SEmployee and
'Kari' is not listed, 'Kari' may or may not be
an employeeNOT S if NOT S is
entailed by the dataRelational data
person:
pid | name | works_for
-----+--------+-----------
1 | Mary | 2
2 | Peter | 3
3 | Carl |
4 | Albert | 1
5 | Mina | 2
6 | Ida | company:
cid | name
-----+------------------------
1 | Albert Inc
2 | North Analytics
3 | Computers and ProgramsDefine:
Now unemployed will contain:
pid | name
-----+------
3 | Carl
6 | IdaMapped to RDF:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix exd: <http://example.org/data/> .
@prefix exo: <http://example.org/ont/> .
exd:person1 a exo:Person ;
rdfs:label "Mary" ;
exo:works_for exd:company2 .
exd:person2 a exo:Person ;
rdfs:label "Peter" ;
exo:works_for exd:company3 .
exd:person3 a exo:Person ;
rdfs:label "Carl" .
exd:person4 a exo:Person ;
rdfs:label "Albert" ;
exo:works_for exd:company1 .
exd:person5 a exo:Person ;
rdfs:label "Mina" ;
exo:works_for exd:company2 .
exd:person6 a exo:Person ;
rdfs:label "Ida" .
exd:comany1 a exo:Comany ;
rdfs:label "Albert Inc" .
exd:comany2 a exo:Comany ;
rdfs:label "North Analytics" .
exd:comany3 a exo:Comany ;
rdfs:label "Computers and Programs" .Adding e.g. the following OWL-ontology:
exo:works_for rdfs:domain exo:Employed
exo:Person SubClassOf exo:Employed or exo:Unemployed
exo:Employed and exo:Unemployed SubClassOf owl:Nothingand querying (with reasoning) for all instances of
exo:Unemployed would give no results.